# 简介
数据库太慢 笔记基于solr 9.11.0
# 启动
bin目录下
solr start
后台url (opens new window) 
# 创建core
solr create -c name name是自定义的core名字 创建的core文件在: ~\solr-8.11.0\server\solr
# 配置schema
# 方法一,直接修改配置文件
core目录下conf下managed-schema文件
uniqueKey不能改
java里面的int 对应solr的pint,注意id必须是tring
# 方法二,通过网络请求
可以用postman添加字段,post方法 http://localhost:8983/solr/user_core/schema id本身就有,因此id不用再添加
{
"add-field":
{
"name":"name",
"type":"string",
"stored":"true"
},
"add-field":
{
"name":"email",
"type":"string",
"stored":"true"
},
"add-field":
{
"name":"phone",
"type":"string",
"stored":"true"
},
"add-field":
{
"name":"sex",
"type":"pint",
"stored":"true"
},
"add-field":
{
"name":"password",
"type":"string",
"stored":"true"
},
"add-field":
{
"name":"age",
"type":"pint",
"stored":"true"
},
"add-field":
{
"name":"create_time",
"type":"string",
"stored":"true"
}, "add-field":
{
"name":"update_time",
"type":"string",
"stored":"true"
},
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
成功返回:
{
"responseHeader": {
"status": 0,
"QTime": 537
}
}
2
3
4
5
6
core目录下conf下managed-schema文件 450行左右已经增加字段描述
<field name="_nest_path_" type="_nest_path_"/>
<field name="_root_" type="string" docValues="false" indexed="true" stored="false"/>
<field name="_text_" type="text_general" multiValued="true" indexed="true" stored="false"/>
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="age" type="pint" stored="true"/>
<field name="create_time" type="string" stored="true"/>
<field name="email" type="string" stored="true"/>
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
<field name="name" type="string" stored="true"/>
<field name="password" type="string" stored="true"/>
<field name="phone" type="string" stored="true"/>
<field name="sex" type="pint" stored="true"/>
<field name="update_time" type="string" stored="true"/>
2
3
4
5
6
7
8
9
10
11
12
13
# 中文分词器
# 倒排索引
倒排索引又叫反向索引(inverted index),既然有反向索引那就有正向索引(forward index)了。一些相关概念可以看前文信息检索(Information Retrieval)相关概念
自带分词器比较弱 ~\solr-8.11.0\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-8.11.0.jar 复制jar包到: ~\solr-8.11.0\server\solr-webapp\webapp\WEB-INF\lib
<fieldType name="text_hmm_chinese" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
2
3
4
5
6
7
8
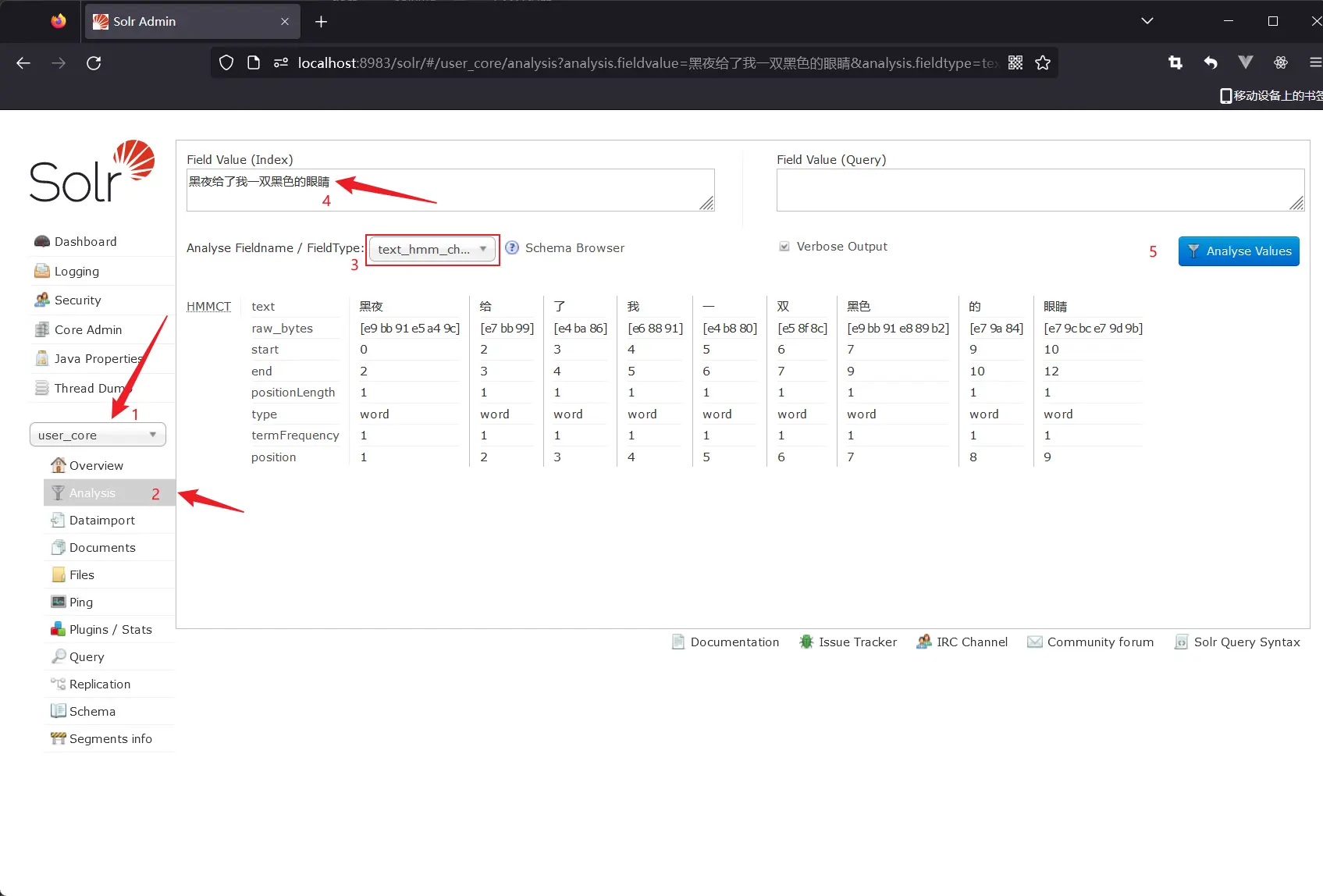
启动Solr服务测试分词;
solr restart -p 8983
# 配置第三方分词器
- 下载jar包 (opens new window),GitHub地址:https://github.com/magese/ik-analyzer-solr
- 将ik-analyzer-8.5.0.jar放置在webapp/WEB-INF/lib/目录下
- 将resources目录下的5个配置文件放入solr服务的Jetty或Tomcat的webapp/WEB-INF/classes/目录下
- 配置Solr的managed-schema,添加ik分词器,示例如下;
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
2
3
4
5
6
7
8
9
10
11
结果比较
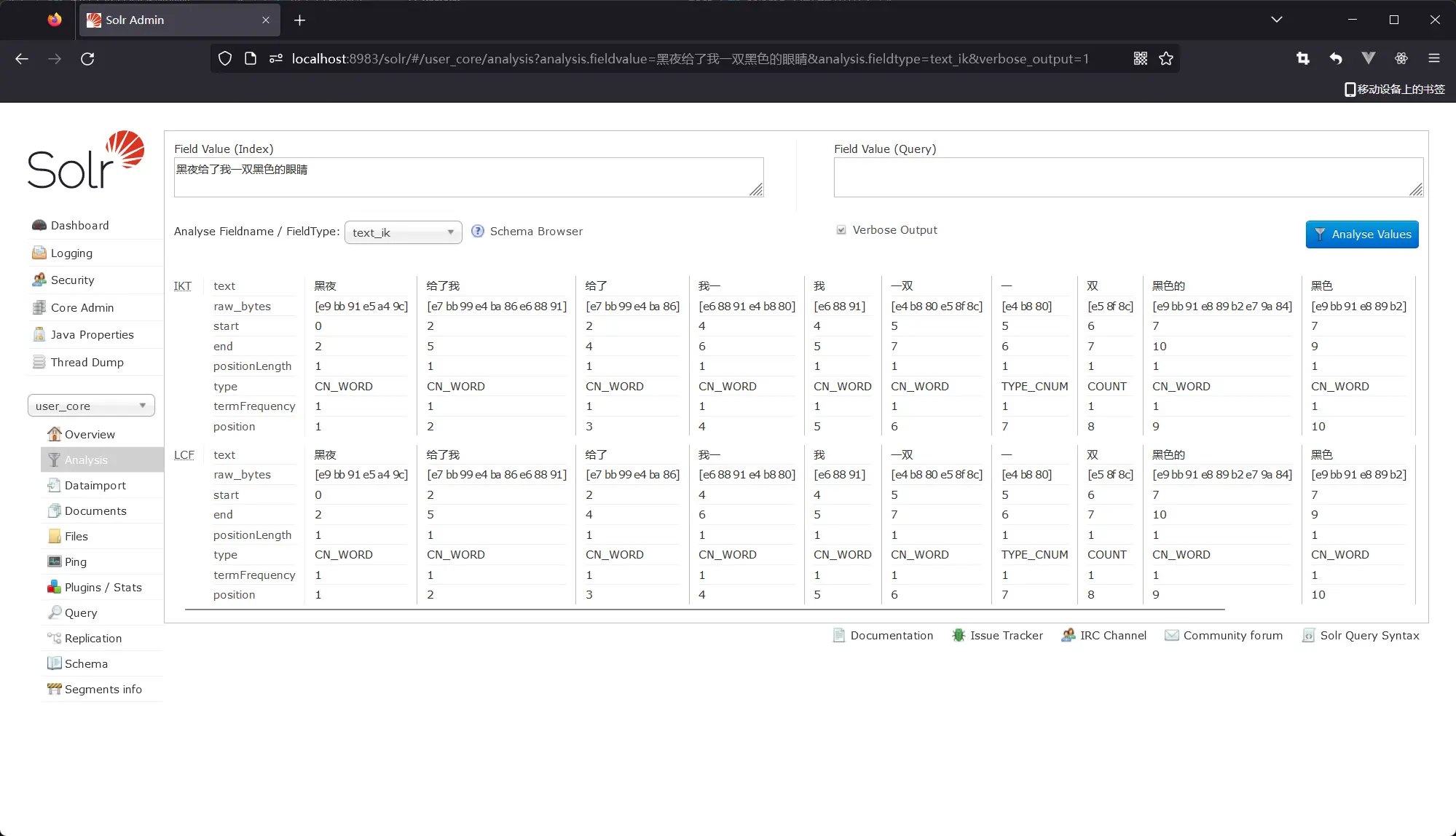
# 分词查询
以message为例,需要设置type为text_ik indexed ="ture"
<field name="_nest_path_" type="_nest_path_"/>
<field name="_root_" type="string" docValues="false" indexed="true" stored="false"/>
<field name="_text_" type="text_general" multiValued="true" indexed="true" stored="false"/>
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="from_user" type="string" stored="true"/>
<field name="to_user" type="string" stored="true"/>
<field name="title" type="string" stored="true"/>
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
<field name="message" type="text_ik" multiValued="true" stored="true" indexed="true"/>
<field name="send_time" type="string" stored="true"/>
<field name="read_time" type="string" stored="true"/>
<field name="phone" type="string" stored="true"/>
<field name="status" type="string" stored="true"/>
2
3
4
5
6
7
8
9
10
11
12
13
配置好后,重启,message:中午多云 不需要加*
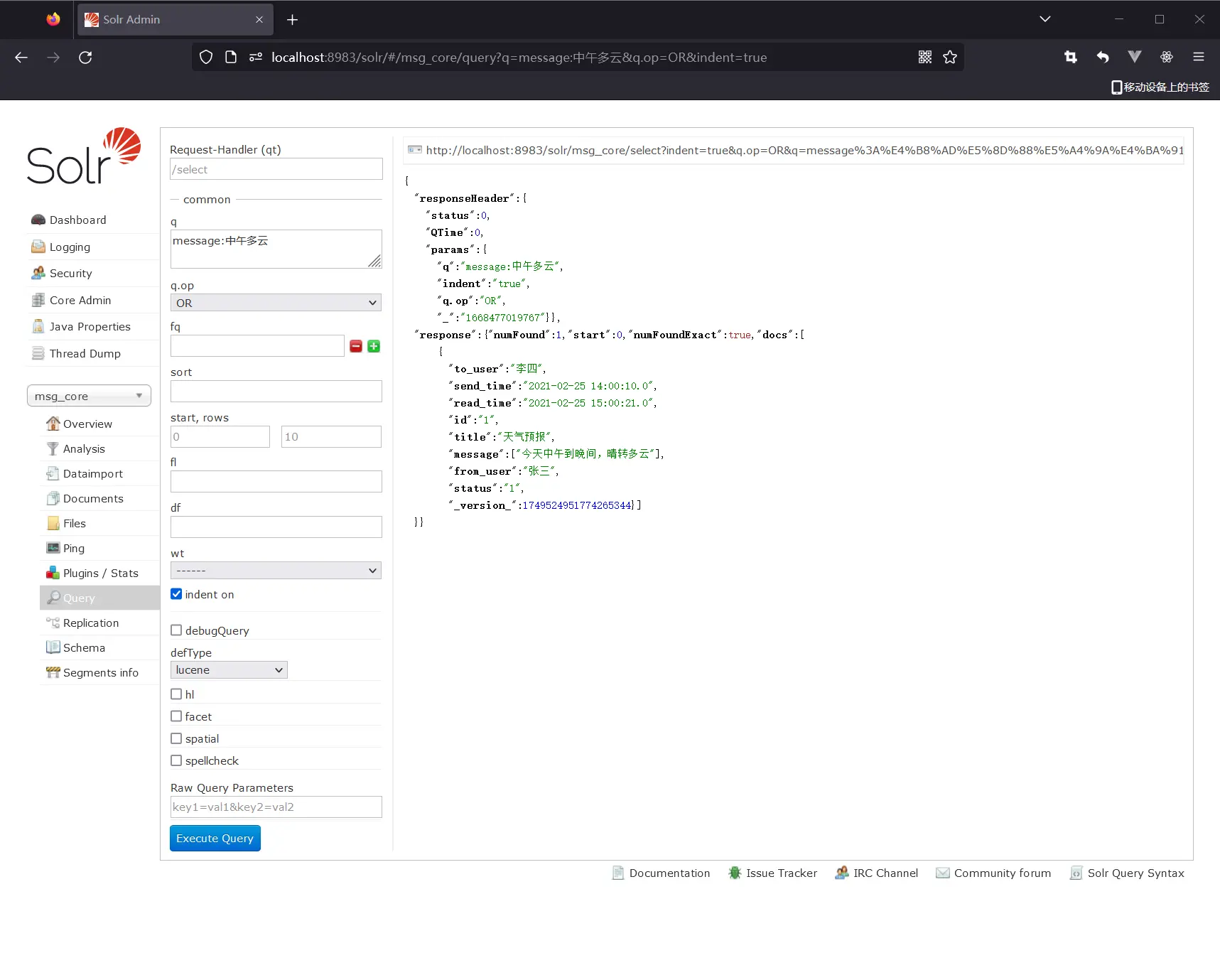
# 导入数据DIH
DIH全称是Data Import Handler 数据导入处理器,顾名思义这是向solr中导入数据的,我们的solr目的就是为了能让我们的应用程序更快的查询出用户想要的数据,而数据存储在应用中的各种地方入xml、pdf、关系数据库中,那么solr首先就要能够获取这些数据并在这些数据中建立索引来达成快速搜索的目的,这里就列举我们最常用的从关系型数据库中向solr导入索引数据。 新版本要移除这个功能 ~\solr-8.11.0\server\solr\user_core\conf solrconfig.xml添加配置
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler>
2
3
4
5
~\solr-8.11.0\server\solr\user_core\conf db-data-config.xml配置数据源
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/solr" user="root" password="mysql" />
<document>
<entity name="user" query="select * from t_user" pk="id">
<field column="id" name="id" />
<field name="age" column="age" />
<field name="create_time" column="create_time" />
<field name="email" column="email" />
<field name="name" column="name" />
<field name="password" column="password" />
<field name="phone" column="phone" />
<field name="sex" column="sex" />
<field name="update_time" column="update_time" />
</entity>
</document>
</dataConfig>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 添加驱动
- 复制Solr解压后dist目录中的:solr-dataimporthandler-8.11.0粘贴到contrib/dataimporthandler/lib目录下, lib目录需要手动创建。
- 复制所用数据库服务器的相应jar包粘贴到contrib/db/lib目录下, db/lib目录需要手动创建。
solrconfig.xml添加驱动
<!-- 配置加入数据导入、数据库驱动的jar包 -->
<lib dir="${solr.install.dir:../..}/contrib/dataimporthandler/lib" regex=".*\.jar"/>
<lib dir="${solr.install.dir:../..}/contrib/db/lib" regex=".*\.jar"/>
2
3
默认0.5g内存 启动时需要增加内存 solr restart -p 8983 -m 6g 否则导入数据时会报内存溢出错误
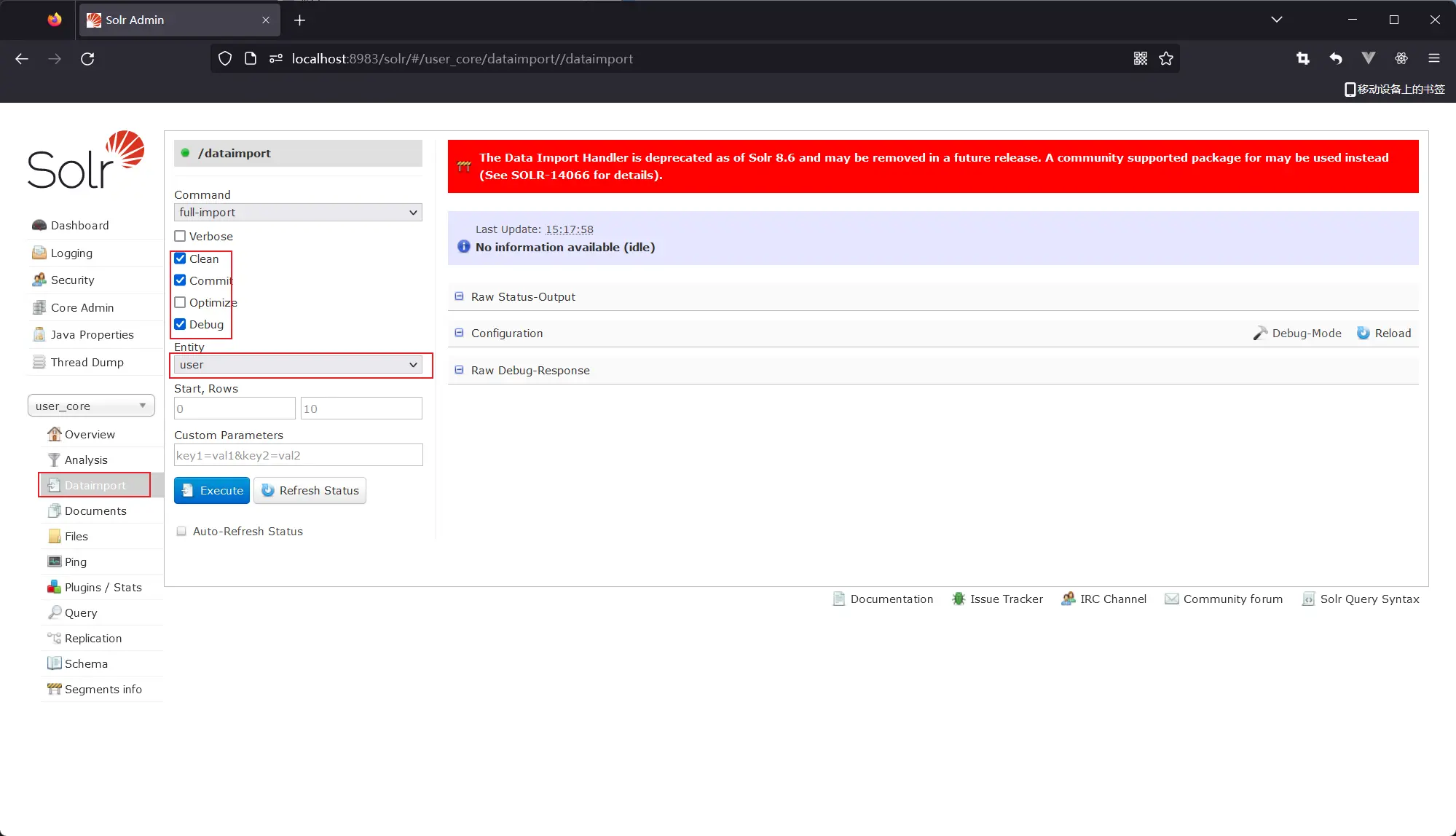
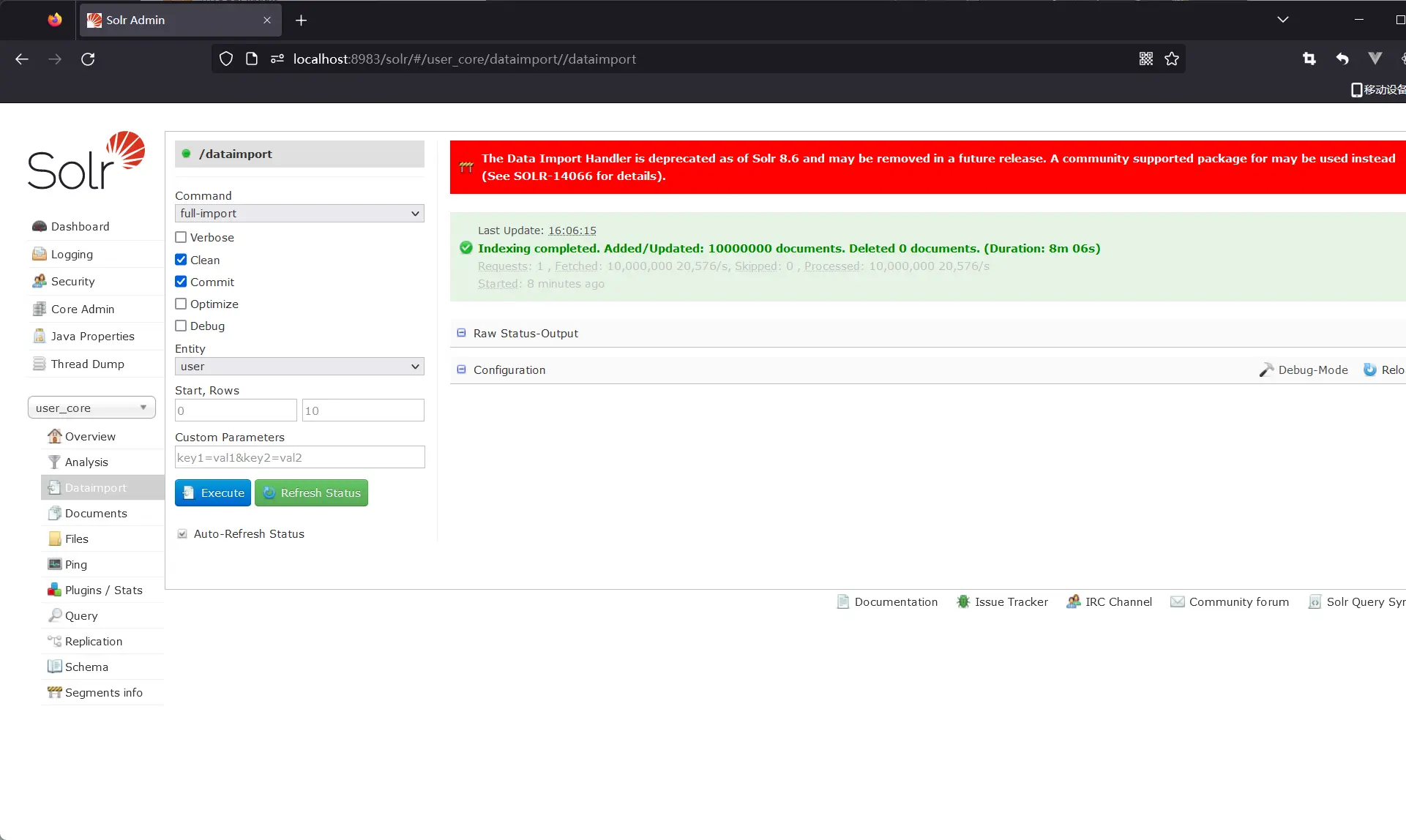 mysql需要7.4s
mysql需要7.4s
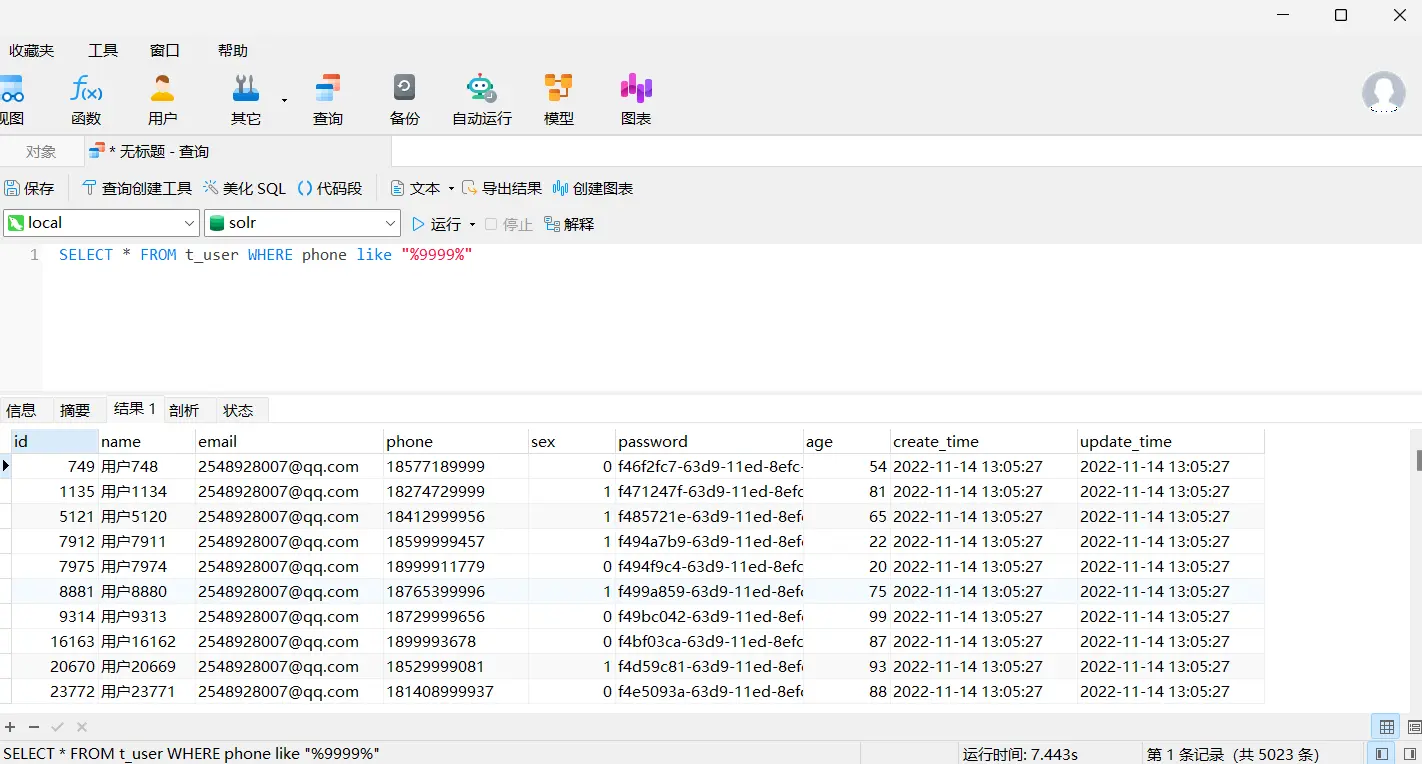 solr,瞬间就出来了
solr,瞬间就出来了
# spring Boot 集成solr
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
<version>2.4.13</version>
</dependency>
2
3
4
5
vo
package com.zr.vo;
import org.apache.solr.client.solrj.beans.Field;
import org.springframework.data.solr.core.mapping.SolrDocument;
import java.util.Date;
@SolrDocument(collection = "user")
public class User {
@Field("id")
private String id;
@Field("name")
private String name;
@Field("email")
private String email;
@Field("phone")
private String phone;
@Field("sex")
private Integer sex;
@Field("age")
private Integer age;
@Field("password")
private String password;
@Field("create_time")
private String createTime;
@Field("update_time")
private String updateTime;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public Integer getSex() {
return sex;
}
public void setSex(Integer sex) {
this.sex = sex;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getCreateTime() {
return createTime;
}
public void setCreateTime(String createTime) {
this.createTime = createTime;
}
public String getUpdateTime() {
return updateTime;
}
public void setUpdateTime(String updateTime) {
this.updateTime = updateTime;
}
@Override
public String toString() {
return "User{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", email='" + email + '\'' +
", phone='" + phone + '\'' +
", sex=" + sex +
", age=" + age +
", password='" + password + '\'' +
", createTime=" + createTime +
", updateTime=" + updateTime +
'}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
controller
package com.zr.controller;
import com.alibaba.fastjson.JSON;
import com.zr.vo.User;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
@RestController
public class UserController {
@Autowired
private SolrClient solrClient;
@RequestMapping("/query")
public String query(String phone) {
List<User> msgList = new ArrayList<>();
SolrQuery solrQuery = new SolrQuery();
solrQuery.set("q", "phone:*" + phone + "*");
solrQuery.setRows(100000000);//分页
try {
Long begin = System.currentTimeMillis();
QueryResponse queryResponse = solrClient.query(solrQuery);
if (queryResponse != null) {
msgList = queryResponse.getBeans(User.class);
}
Long end = System.currentTimeMillis();
System.out.println(end - begin);
} catch (Exception e) {
e.printStackTrace();
}
return JSON.toJSONString(msgList);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 查询
- AND需要大写
- fq多条件查询,对q结果的过滤 https://blog.csdn.net/qq_42418169/article/details/112471891
# 增删改
@PostMapping("/add")
public String add(Msg msg) throws SolrServerException, IOException {
solrClient.addBean(msg);
solrClient.commit();
return "";
}
@PostMapping("/edit")
public String edit(Msg msg) throws SolrServerException, IOException {
solrClient.addBean(msg);
solrClient.commit();
return "";
}
@PostMapping("/remove")
public String remove(Msg msg) throws SolrServerException, IOException {
solrClient.deleteById(msg.getId());
solrClient.commit();
return "";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 分词
使用的分词器在配置文件中与字段绑定的
/**
* 中文分词
* @param value
* @return
*/
@RequestMapping("/analyse")
public String analyse(String value){
FieldAnalysisRequest request = new FieldAnalysisRequest("/analysis/field");
request.addFieldName("message");// 字段名,随便指定一个支持中文分词的字段
request.setFieldValue("");// 字段值,可以为空字符串,但是需要显式指定此参数
request.setQuery(value);
FieldAnalysisResponse response = null;
try {
response = request.process(solrClient);
} catch (Exception e) {
e.printStackTrace();
}
List results = new ArrayList();
Iterator<AnalysisResponseBase.AnalysisPhase> it = response.getFieldNameAnalysis("message").getQueryPhases().iterator();
if(it.hasNext()) {
//ik分词会有两个结果,一个为IKT,一个为CLF
AnalysisResponseBase.AnalysisPhase analysisPhase = it.next();
List<AnalysisResponseBase.TokenInfo> list = analysisPhase.getTokens();
for (AnalysisResponseBase.TokenInfo info : list) {
results.add(info.getText());
}
}
return results.toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 其余
增删改的时候,先操作solr,再操作mysql 查询只查询solr就可以
# solr挂了
查询MySQL 修复后同步一下数据,可以修改导入sql添加筛选时间条件
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=38dpnhkh4o8wo